This post is a first. Up to now, all content on this blog has been exclusively written by myself. But recently Nick Mehlig and Ben Names from Structural Design and Analysis, Inc. (SDA), a team of stress engineers that design lightweight and load efficient structures, contacted me with a proposal for a guest post. The reason why I agreed is because the guys at SDA have a unique perspective on a fascinating real-world engineering problem — re-designing the wing of a Fokker D-VII. The Fokker D-VII was a German fighter aircraft in World War I but was also used by many other countries after the Great War. This post is a look at some of the details of how aircraft components are designed.

Within the Aerospace Engineering community, there is an entire sub-discipline devoted to understanding the dynamics of a system and how loads are generated (propulsive, inertial, aerodynamic, etc). In smaller companies, engineers often need to wear multiple hats, and the lines between classical stress analysis and aerodynamic loads analysis begin to blur. Recently, Structural Design and Analysis, Inc. (SDA) worked with a local resident who had taken it upon himself to build a Fokker D-VII Biplane from scratch, and wanted to know how much weight he could save if he used an aluminium spar for the main wings instead of the original wooden spar design.
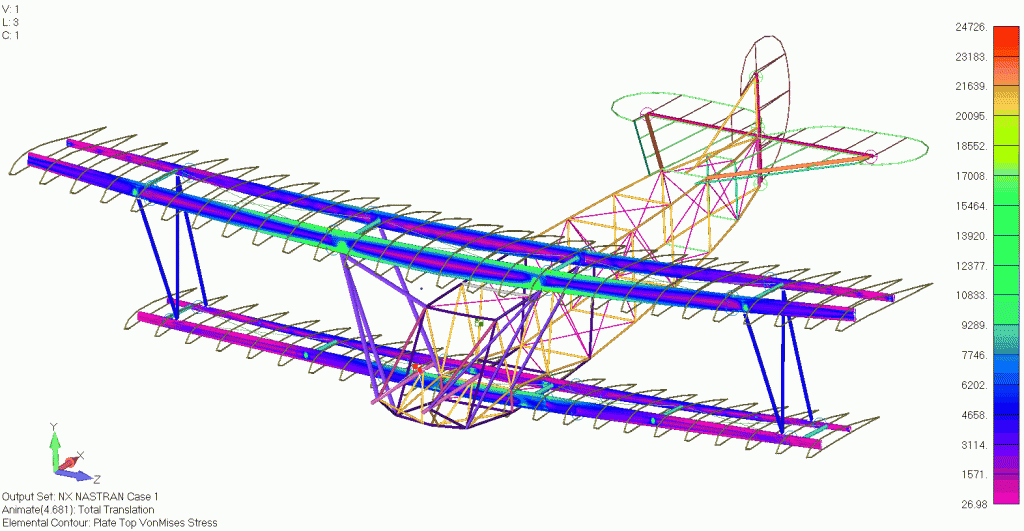
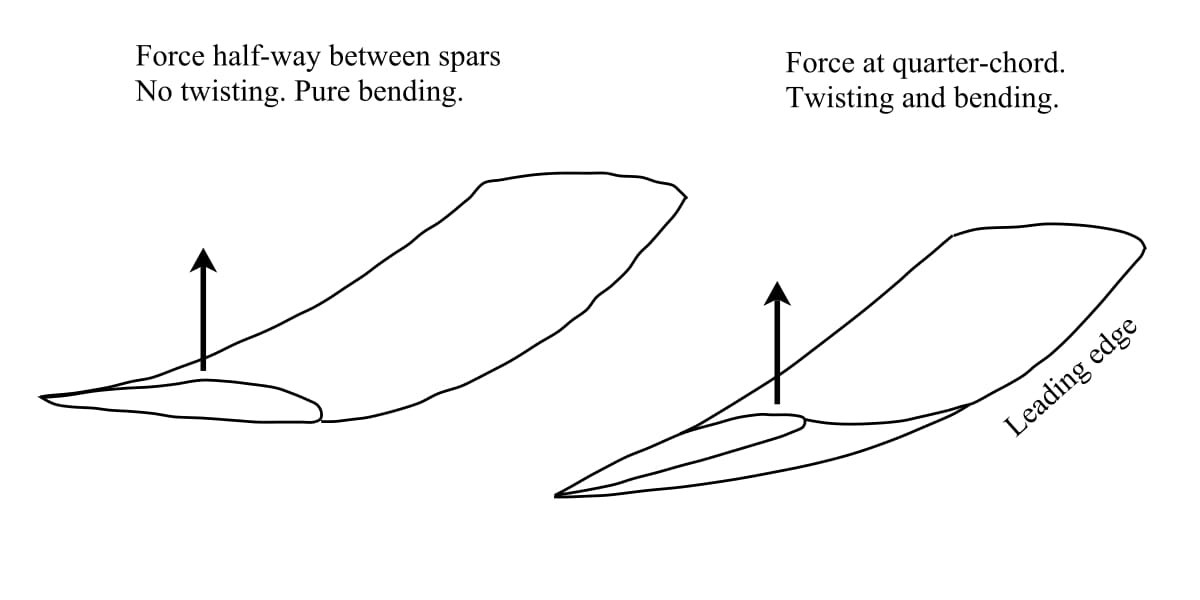
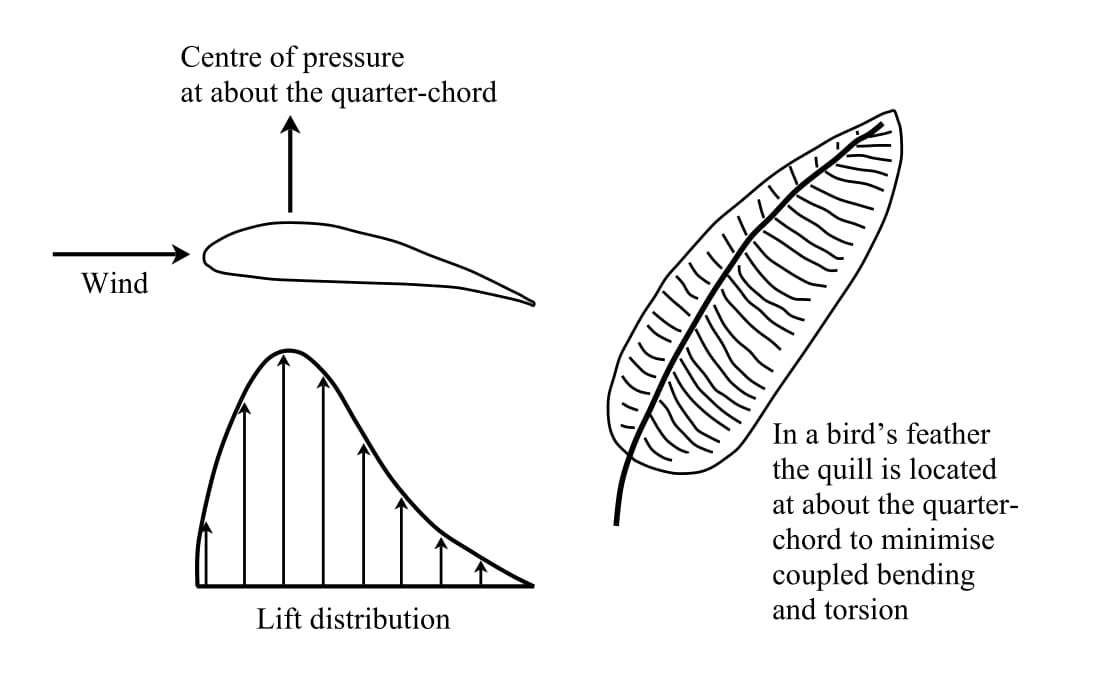
Our engineers had to develop a finite element model (FEM) and conduct the basic loads and dynamics analysis to define the load cases for the vehicle. Generating aerodynamic loads is relatively straight forward for aircraft with more conventional designs. Typically, a combination of 2D aerodynamic theory and corrections for wings with finite span are used to generate the loads in the early stages of the design phase. These loads are then applied to the structure at the quarter chord location of the wing. For the Fokker, this analysis is slightly more complicated because the biplane construction creates interference effects between the upper and lower wing which must be considered when determining the loads that act on the aircraft.

The goal of this case study is to show that various approaches can be taken to solve this loads-generation problem, and that the “best” approach for an engineer depends on his/her technical expertise, available resources (time and/or money), and the desired accuracy of the results. Three different methods were selected to calculate the aerodynamic loading on the Fokker D-VII biplane, and they are listed in increasing order of required technical expertise and accuracy:
- Assuming that each wing can be analysed separately. This type of solution is best suited to an aircraft enthusiast or an engineer without much background in theoretical aerodynamics.
- Accounting for the interaction between the upper and lower wing using correction factors. This type of solution is best suited for an engineer with a level of understanding comparable to an undergraduate education in aerospace engineering.
- Using an advanced FEM analyses suite such as NX Nastran’s Static Aeroelastic SOL 144. This solution technique requires the least amount of effort on the user since the loads are calculated internally by NX Nastran, but is best suited to an engineer with some postgraduate education in aerospace engineering.
Let’s compares the efficacy of these three methods and the accuracy of their respective results.
Method 1
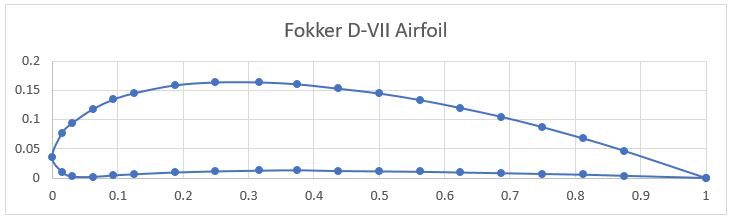
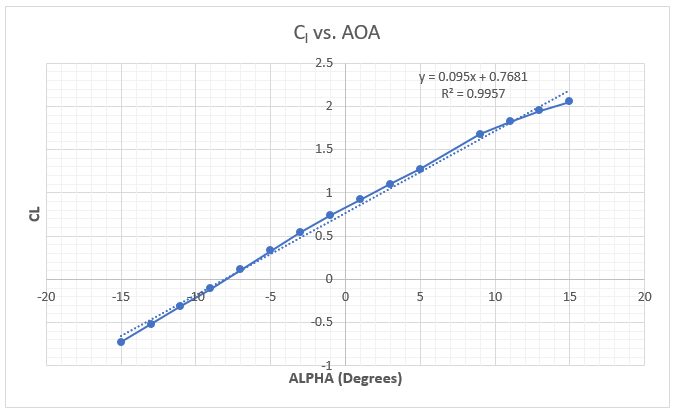
The first step in calculating the aerodynamic loads on the aircraft is to get the airfoil data. The Fokker D-VII uses a modified Goettigen GOE 418 airfoil for the upper wing. The airfoil data points (see the diagram below) were imported into XFOIL, a popular open-source 2D potential flow code, and the lift coefficients were extracted for various angles of attack (AOA). Using the XFOIL data, a plot relating the wing’s AOA to the lift coefficient ([latex] C_L [/latex]) is constructed. A trendline is added to the data to estimate the lift curve slope for the airfoil of [latex] C_{L_\alpha} = 0.095/^\circ [/latex] and the zero lift AOA is [latex]-8^\circ[/latex](the airfoil is angled down for no lift).
To calculate the lift on the upper and lower wings, a simple approximation from Prandtl Lifting Line Theory is used which relates the 3D lift coefficient to the 2D lift curve slope, the wing aspect ratio (AR) and the AOA. The lower wing of the Fokker D-VII has a [latex] 1^\circ [/latex] AOA while the upper wing has [latex] 0^\circ [/latex] AOA.
[latex] C_{L,upper} = C_{L_\alpha} \left( \frac{AR}{AR+2} \right) \left( \alpha – \alpha_{0L} \right) = 0.095 \left( \frac{5.14}{5.14+2} \right) \left( 0-(-8)\right) = 0.55 [/latex]
[latex] C_{L,lower} = C_{L_\alpha} \left( \frac{AR}{AR+2} \right) \left( \alpha – \alpha_{0L} \right) = 0.095 \left( \frac{5.67}{5.67+2} \right) \left( 1-(-8)\right) = 0.63 [/latex]
The lift equation was then used to calculate the lifting force on the wings.
[latex] L_{upper} = qS_{upper}C_{L,upper} = (0.277\ psi)(20,418.3\ in^2)(0.55) = 3,110.73\ lb [/latex]
[latex] L_{lower} = qS_{lower}C_{L,lower} = (0.277\ psi)(12,630.72\ in^2)(0.63) = 2,204.19\ lb [/latex]
where [latex] S [/latex] is the wing area and [latex] q = 1/2 \rho V^2 [/latex] is the dynamic pressure that depends on the density [latex] \rho [/latex] and the airspeed [latex] V [/latex] of the particular manoeuvre.
To balance the aircraft, the moment created by the wing lift about the centre of gravity of the Fokker needs to be balanced by the tail wing lift force, [latex] F_{tail}[/latex]. Each moment is equal to the lift force multiplied by the distance of the point of action [latex] x [/latex] from the centre of gravity of the aircraft. Given the relative positions of the two wings and the tail plane, we solve the following equation
[latex] F_{tail} = \frac{L_{lower} x_{lower} – L_{upper} x_{upper}}{x_{tail}} = \frac{3110.73 \times 11.60 – 2239.17 \times 10.41}{190.12} = 79.40\ lb [/latex]
The sum of these three loads is [latex] 3,110.73+2,204.19+79.40 = 5,394.32 [/latex] lb or 4.31g’s. Since we are analysing a 4.0g load case here, the lift on the wings will need to be reduced. As the lift on the wings is reduced, the pitching moment will change which, in turn, changes the required tail force to balance the aircraft. Excel’s goal seek was used to reduce the wing loading and balance the aircraft such that the total lift (including the tail) is equal to 4.0g. The final loads are shown below.
[latex] L_{upper} = 2,894.41 [/latex] lb
[latex] L_{lower} = 2,078.78 [/latex] lb
[latex] F_{tail} = 62.81 [/latex] lb
These final loads are applied to the quarter chord location of the wings. Here, a rectangular spanwise lift distribution is applied to the upper and lower wings.
Method 2
By having two wings subject to the same flow, each wing interacts with the other’s vortex system such that the upper wing experiences an increase in lift and the lower wing experiences a decrease in lift, denoted by [latex] \Delta C_{L,upper} [/latex] and [latex] \Delta C_{L,lower} [/latex] respectively. The following method uses the simple biplane theory which is detailed in NACA Technical Report No. 458 [1]. It is shown that the change in lift coefficient [latex] \Delta C_{L} [/latex] follows a linear relation with the overall vehicle lift coefficient [latex] C_{L} [/latex] in the following form:
[latex] \Delta C_{L,upper} = K_1 + K_2 C_L [/latex]
Where [latex] K_1 [/latex] and [latex] K_2 [/latex] are constants relating to the gap between the two wings, wing stagger (the relative fore-aft position of the two wings), decalage (angle difference between the upper and lower wings of the biplane), overhang (the extension of one wing span over the other), and wing thickness. The change in lift for the lower wing is related to the change in lift of the upper wing by the ratio of wing areas.
[latex] \Delta C_{L,lower} = -\Delta C_{L,upper} \frac{S_{upper}}{S_{lower}} [/latex]
The methods of finding the values of [latex] K_1 [/latex] and [latex] K_2 [/latex] follow a graphical approach using the biplane ratios of wing gap = 55 in., wing stagger = 25 in. , percent wing overhang = 17.4%, and decalage = 1 deg. Using these values and the method described in NACA Report 458, the following values are calculated: [latex] K_1 = -0.090 [/latex] and [latex] K_2 = 0.195 [/latex]. The final lift coefficient for the upper and lower wings are found by adding the correction to the vehicle lift coefficient to the original uncorrected value. This uncorrected value is calculated from the maximum weight of the aircraft, which naturally determines the lift required from the wings. The maximum weight of the Fokker D-VII is 1,259 lbs, and for a 4.0g manoeuvre (n=4 in the equation below), the aircraft lift coefficient is:
[latex] C_L = \frac{nW}{0.5 \rho V^2 S} = \frac{nW}{qS} = \frac{4 \times 1259}{0.277 \times 33049} = 0.55 [/latex]
Plugging in values for [latex] K_1 [/latex], [latex] K_2 [/latex] and [latex] C_L [/latex] into the [latex] \Delta C_{L,upper}[/latex] and [latex] \Delta C_{L,lower}[/latex] equations give the following values:
[latex] \Delta C_{L,upper} = 0.015 [/latex] and [latex] \Delta C_{L,lower} = -0.025 [/latex]
Using the new corrected values for the wing coefficients [latex] C_{L,upper} = C_L + \Delta C_{L,upper}[/latex] and [latex] C_{L,lower} = C_L + \Delta C_{L,lower}[/latex], the total load can be calculated for the upper and lower wings. A moment balance is performed and the following loads are calculated for the aircraft:
[latex] L_{upper} = 3,139.88 [/latex] lb
[latex] L_{lower} = 1,803.24[/latex] lb
[latex] F_{tail} = 92.87[/latex] lb
Again, the loads are applied to the quarter-chord position of the aircraft wings. Two different spanwise lift distributions are applied to the model for this comparison study. The first assumes an elliptical lift distribution. The second uses Schrenk’s Approximation to estimate a more accurate spanwise lift distribution. These two distributions are shown below along with a reference to a rectangular distribution.
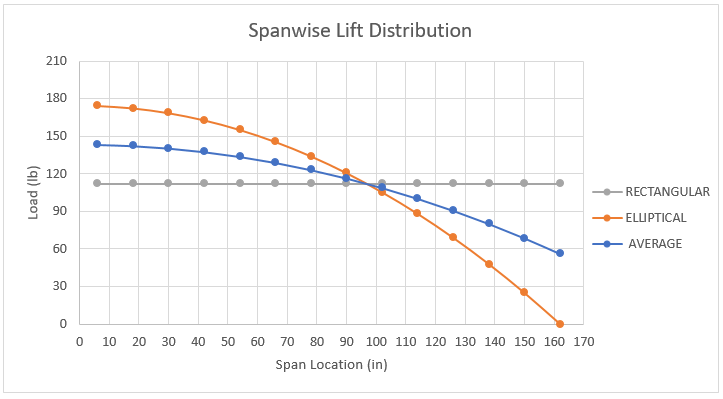
Method 3
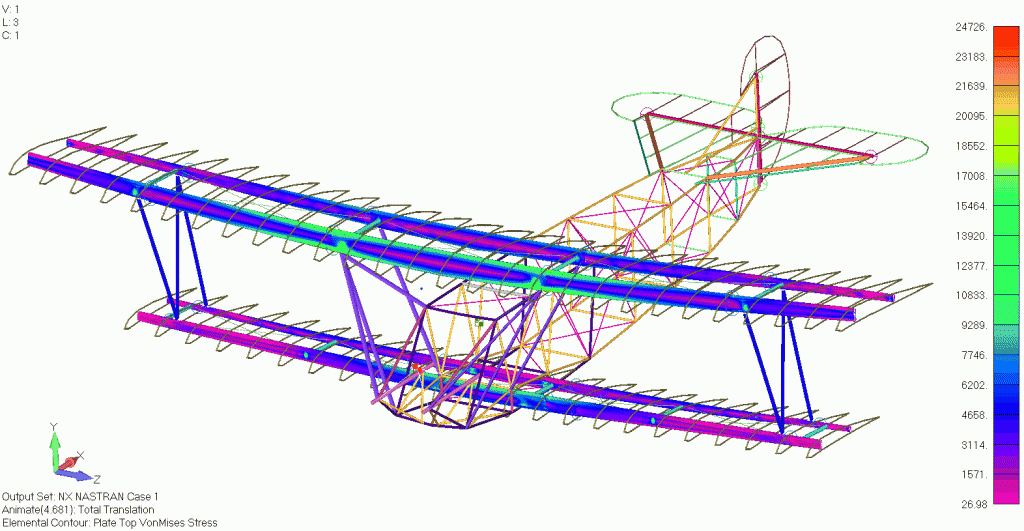
The third and final method is to use NX Nastran’s static aeroelastic SOL 144 analysis to generate the loads using a vortex lattice formulation. A potential flow model is created in FEMAP to generate the aerodynamic loading for the Fokker. One of the powerful functionalities about SOL 144 trim analysis is that given high-level information about any flight condition, Nastran cannot only calculate the aerodynamic forces, but can also ensure that the vehicle is stable. With just a few clicks, the load case can be modified to model any corner of the flight envelope by changing the dynamic pressure and load factor of the aircraft. Since Nastran calculates all the loads internally using this high-level flight condition information, it can save an incredible amount of time that might be devoted to calculating loads externally, bringing them in, and applying them to the structure accurately. This solution requires the least amount of effort on the user since the loads are calculated internally by NX Nastran and then applied to the FEM through the points defined in the model. NX Nastran automatically calculates the trim condition of the aircraft and calculates the loading on the upper wing, lower wing, and horizontal tail. The resulting loads are shown below:
[latex] L_{upper} = 3223.21 [/latex] lb
[latex] L_{lower} = 1,697.10[/latex] lb
[latex] F_{tail} = 122.75 [/latex] lb
Results
As the complexity increases with each of the methods discussed above, so does the accuracy of the results. However, not every stage of the design requires the same precision. Since this discussion focuses on how the analysis approach impacts the design of the aircraft, let us first compare the calculated loads for all three methods. Below is a table outlining the loads for each method and the percentage difference when compared to the aeroelasticity finite element model (the most accurate loads generation approach).
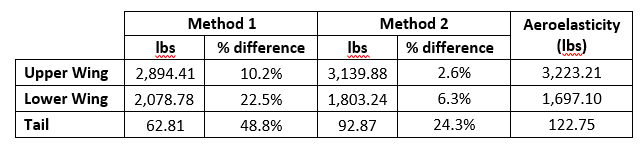
When comparing the lifting force of upper and lower wings of the aircraft, the aerodynamic loading from method 1 underestimates the lift on the upper wing by 10.2% and over estimates the lift on the lower wing by 22.5%. Applying Simple Biplane Theory in method 2 captures the interference effects and estimates the wing loading much more accurately with the upper wing lift only 2.6% less and the lower wing lift 6.3% greater, when compared to the aeroelastic model. A more detailed way to compare the resulting design impact of the three different load generation methods is to look at the internal shear and bending moment diagrams within the spars. Below is the shear force diagram for the upper wing leading edge spar.
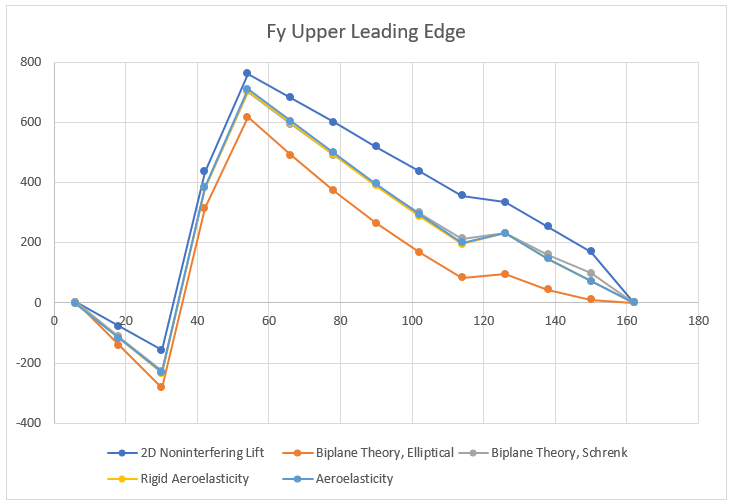
Starting with the simplest method, the 2D non-interfering lift generates the highest shear force. As one would expect the variation in the maximum internal shear force is small (at most 7% difference) over all the models since the total lift generated by the plane was set to be constant. The differences are partially due to how the lift is distributed between the upper and lower wings. Furthermore, the spanwise distribution clearly has an impact on the internal shear force. Interestingly, the model that matches the shear force of the aeroelasticity model the closest is the Biplane Theory model using Schrenk’s approximation. The differences produced by these aerodynamic models becomes even more apparent when inspecting the internal bending moment.
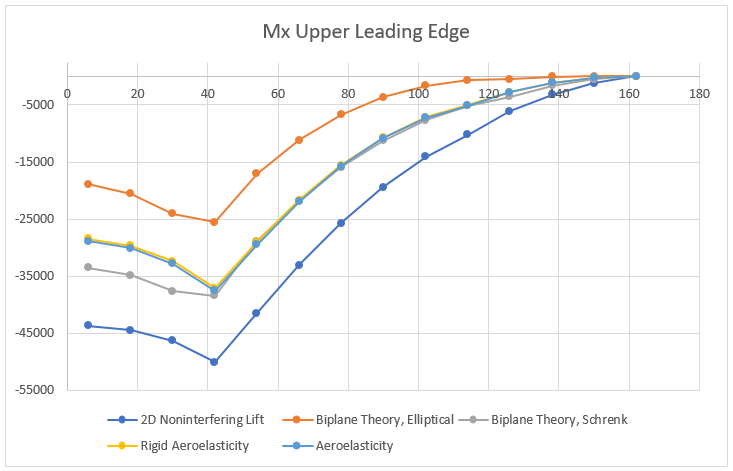
The internal bending moment clearly shows how differences in the aerodynamic models can propagate. The most basic model (2D Non-interfering Lift) produces the highest bending moment, 33% higher than the aeroelastic solution. While it is safer to be on the conservative side, this kind of inaccuracy will lead to a substantially heavier structure, thus limiting performance.
The shear and bending moment diagrams are often excellent indicators of the internal stress state within simple structures. As a stress engineer, comparing stress plots is the most meaningful way to compare how the different aerodynamics models impact the stress throughout the vehicle. Below is a picture of the upper wing leading and trailing edge spars Von Mises stress under a 4g pull up when using the aeroelasticity model.
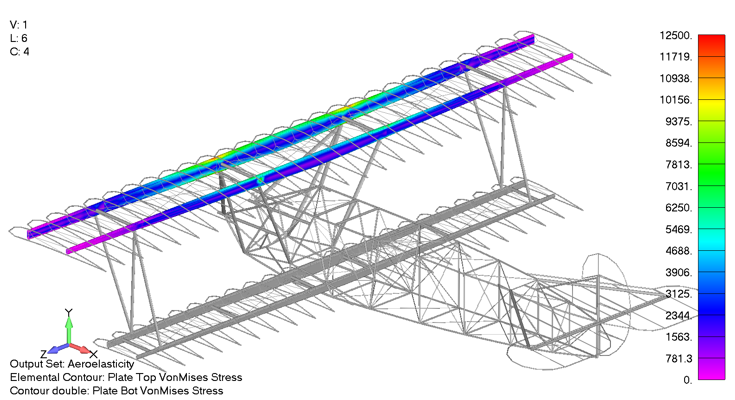
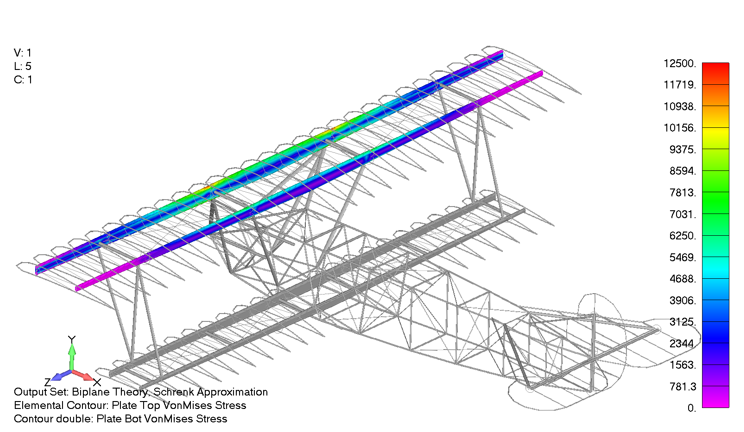
The max spar cap Von Mises stress is 11.4 ksi. In comparison, the same stress contour is presented below, only for the case using the Biplane theory using Schrenk’s approximation, which exhibited a maximum Von Mises stress of 11.5 ksi, a 0.8% difference from the aeroelastic aerodynamic model.
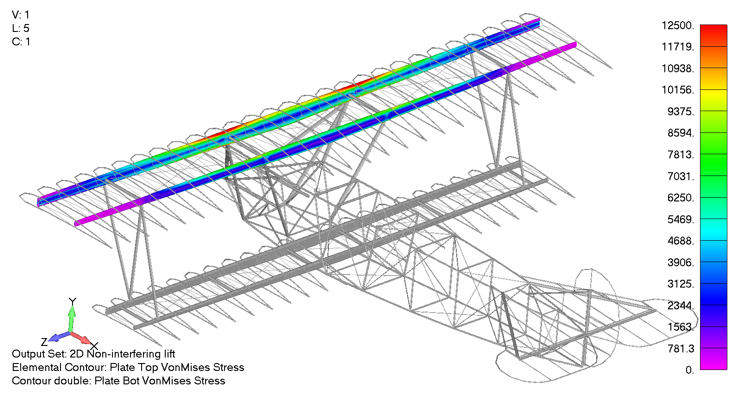
In contrast, the Von Mises stress state for the upper wing under the 2D non-interfering lift can be seen below as a gross overprediction, predicting a maximum Von Mises stress of 15.2 ksi, 33% higher than the aeroelastic aerodynamic model.
Conclusion
Having exhaustively explored the impact of different aerodynamic models on the final stress results, several conclusions have become clear. First and foremost, as laid out at the beginning, none of these approaches are inherently bad. However their mileage does vary significantly. Requiring the least technical background, the 2D non-interfering lift model provides a good approximation of the stress state in the leading and trailing edges, but is over-conservative in predicting internal stresses. As expected, including the interference effects between the upper and lower wing in the simple Biplane Theory and applying finite span effects has the potential to predict stresses within 0.8% of the most accurate model. Unfortunately, this relies on the user correctly calculating the span wise loading and interference effects which often requires complex analytical methods or using a potential flow method. Furthermore, there are ample opportunities for an engineer to make a mistake when taking this approach, and it could be difficult to detect these without the results of a more accurate model to compare to.
Now, given that fairly accurate stress distributions using semi-analytical methods can be achieved, you might be asking yourself, why might anyone want to spend the money to use the NX Nastran Aeroelasticity module? First, it removes substantial uncertainty in the accuracy of the aerodynamic model. The Nastran Aeroelasticity module can account for interfering lifting surfaces, slender fuselage effects, ground effect, compressibility, wing sweep and taper, as well as a number of other factors. Additionally, once implemented, the Nastran Aeroelasticity module is more flexible than generating the loads from an outside source and then applying those loads within FEMAP (the pre/post environment). Nastran can generate the loads for any flight condition such as steady level flight, a 4g pull up, or a 3g coordinated turn, requiring only high level information from the user.
Finally, the user is also provided with additional information such as the trim angle of attack, control surface deflection angles, and vehicle stability derivatives. As with most problems, there is rarely a single correct approach, but when high accuracy and case-generation flexibility are desired, then using NX Nastran’s Static Aeroelastic Solution 144 is the way to go. However, if you are working on a budget, can take on additional mass, or do not have the technical background to employ Solution 144, then using an analytical method or generating the loads some other way externally is probably the way to go.
References
[1] Diehl, W. S., “Relative Loading on Biplane Wings,” NACA TR-458, January 1934
by Prof. J E Gordon






.jpg)







.jpg)